AI Data Center Boom Brings Massive Fiber Multipliers


AI Data Center Boom Brings Massive Fiber Multipliers
“I am your density!” – George McFly, Back to the Future
The quest for useful and productive Artificial intelligence (AI) is becoming an all-consuming vision for the data center industry that is driving unprecedented scale and construction and coining new terms such as neoclouds as well as new currency in the form of tokens. Building better, faster, and more efficient facilities to house hundreds of thousands of GPUs under one roof is pushing the networking and fiber industries to pack more fiber into servers, racks, buildings, and networks to train the next generations of AI models at a rate that few could have imagined or envisioned five years ago.
For example, Meta’s Hyperion Data Center is being built on 2,250 acres of land in Northeast Louisiana, something that will rival the surface area of the island of Manhattan. Expected to be operational by 2030, the four million square foot facility is expected to create 500 or more direct new jobs, more than 1,000 indirect jobs, and employ 5,000 construction workers at peak. It will deliver over 2 gigawatts of computing capacity to train Meta’s future open source large language models.
It should be no surprise that Corning announced a multi-year deal with Meta worth up to $6 billion to supply the company with its newest innovations in optical fiber, cable, and connectivity solutions. The deal, and no doubt others that have not been publicly disclosed, will support Corning expanding manufacturing capabilities across North Carolina, with Meta as the anchor customer for a new factory in Hickory, North Carolina.
Vendors from across the fiber ecosystem announced their latest innovations at the OFC conference this year on March 15-19, 2026, presenting their latest connectivity building blocks for top tier cloud providers such as Amazon, Apple, Google, Meta, Microsoft, OpenAI, and Oracle to build massive computational complexes in the United States and around the globe over the next five years. When completed, these facilities will be difficult to reproduce or rival given the sheer amount of resources in computer chips, storage, power, water, land, and yes, fiber, they will consume.
There’s no one place where fiber isn’t present in the AI GPU density gold rush, with vendors putting in more glass at increasing multiples to the server, rack, building, campus, metro, and middle-mile networks. More fiber means lower operational costs, increased reliability, and the ability to rapidly scale speeds for today and tomorrow.
Stripping to the essentials
Corning and other vendors have reevaluated their fiber density targets and innovations focus to squeeze as many strands into as little space as possible, reducing cable and ribbon diameter while making it easier and faster to install.
For example, at OFC, Corning announced its Corning(R) Contour(TM) Flow micro cable which built around Corning’s SMF-28® smaller diameter fiber with improved bend resilience. A single strand of stock “old” fiber has an outer diameter of 242 microns, while SMF-28 has a diameter of 190 microns, a cross-sectional area reduction of 40%.
Booting Up the Beginning
Out of band management (OOBM) isn’t very flashy, but the ability to access and control thousands of servers via console is essential for startup, diagnostics, and shutdown. Once the job of legacy switch and console servers built around copper, with wiring between servers to switches and more wiring between switches at the top of the rack and across racks to connect everything together, companies such as Ciena and Nokia have taught the OOBM dog a new trick, replacing copper with a PON solution that reduces power, space, management time, and provides some additional security layering.
“If you compare [PON-based OOBM] to traditional technologies, there’s really three major benefits,” said Stefaan Vanhastel, Head of Marketing & Innovation, Fixed Networks at Nokia. “It’s more than 50% more power efficient, lower energy consumption. You save about 90% in space because you’re replacing switches out of band in every rack with an ONT, and you reduce the operational effort to install and maintain them by about 80% since these ONTs are managed as part of the PON network through OMCI, and you don’t need to log into switches independently, configure them, provision them, etc. It happens automatically.”
Since the OOBM PON network operates on different technology on a separate network, it presents additional hardware and software challenges for various types of cyberattacks. Nokia’s solution, announced at OFC, runs XGS-PON and is capable of easily supporting up to 25,000 servers using a single optical switch. From a space perspective, 2U of optical equipment would replace 86U of Ethernet switches (more than two racks), freeing up space, power, and cooling for more GPUs and/or other resources in the data center,
Another solution that Nokia and others are working with includes a canopy equipment mount that wouldn’t have to be rack-mounted and could instead be placed at the top of the rack. Since the optical equipment is passively cooled and designed to be used in outdoor environments, it has increased durability over stock data center equipment.
Increasing Density Within the Data Center
Placing more GPUs per square foot of data center space is top of mind for every party involved in the AI construction race, improving on the Small Form-factor Pluggable (SFP) optics gear, first established in 2001 for high-speed copper and fiber connections through a multi-source agreement (MSA). The latest version, the OSFP module, was established in 2016 to service all optical standards on the market and speeds up to 1600G, with 32 modules able to fit in a 1U front panel.
“OSFP has become the highest volume and highest revenue optics module in history,” said Andreas Bechtolsheim, Co-founder and Chief Architect of Arista Networks. “But there’s a problem. It’s no longer dense enough for the needs of AI.”
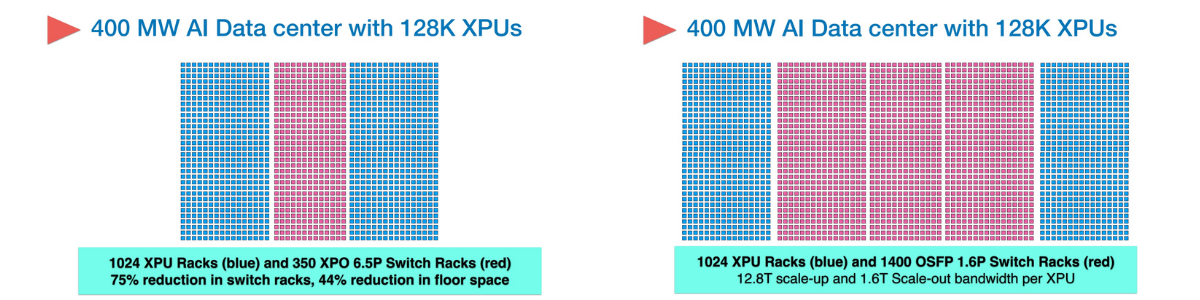
Using current OSFP technology, there are more racks needed for switches and connectivity than XPU nodes. XPO, introduced at OFC 2026, delivers a striking reduction in racks and floor space, freeing up room for more compute. Source: Arista Networks
The two problems with OSFP are physical space and cooling, said Bechtolsheim, since simply packing more chips together would cause thermal problems by relying on fan and cold plate heat sinks. Building a switch with 128 1600G-OSFP connections would require a 4U chassis, which grows to a substantial footprint.
XPO is the new standard optics manufacturers are rallying behind to make the next leap in data center connectivity at the rack level. Short for “eXtra-dense Pluggable liquid cooled Optics Module,” it uses a combination of new approaches to increase rack fiber network density by a factor of four.
“The future AI data centers are all 100% liquid cooled, and so do the switches that have to go into these data centers,” said Bechtolsheim. “Our target here was to improve front panel density by four. And obviously on top of that, you have to solve the problem across different networks needed for AI infrastructure – scale up, scale out, scale across to interconnect GPUs. Everybody wants higher reliability, these things break way too often. Everybody wants the best power efficiency, though, basically all these things all at once have to be solved.”
Adding liquid cooling and compressing the form factor results in the ability to put 16 XPO modules, with each XPO module carrying 64 channels at 200G into a 1U Open Rack form factor. This results in a total of 204.8 Tbps of switch capacity in 1 OU; the Open Compute Project 1U size is slightly larger than a standard 19-inch data center rack. “The cooling connectors are quick disconnects, spring loaded mechanism, so when you pull it out, the liquid stays inside the module and nothing leaks,” stated Bechtolsheim. “
Moving from OSFP to XPO drastically changes the way AI and other hyperscale data centers will be designed and built. To service 512 GPUs (or more generically XPUs for accelerators) with 25.6T of connectivity per XPU would require 8 OSPF switch racks, taking up more space than the 4 racks of XPU servers. XPO changes the rack equation to 2 racks of network connectivity and 4 racks of XPU servers, reducing the AI cluster footprint by half.
At scale in large AI campuses, XPO will deliver significant benefits while increasing fiber connectivity. “The savings here, what we call the benefit of switch densification, you’re saving roughly half the footprint of all these data centers being built, saving billions of dollars across the industry,” Bechtolsheim said. More importantly, at the network rack level, you’re saving 75% of the racks. Each rack is not just the metal of the rack; it’s the bus bars, the power shelves, the manifolds. By the time a rack is plugged in, it’s a fairly expensive thing. We really wanted to take advantage of the cooling capability.”
Other benefits include shorter-cable reaches for scale-up fabrics, which is critical for the lowest power devices in the overall build, and the ability to support large switch topologies in a single rack. Combined with the higher reliability by reducing the part count when compared to OSFP and operating at lower temperatures makes XPO a standard that over 60 vendors have endorsed through a MSA at OFC in March, including the top optics module vendors. XPO systems are expected to be in production by 2027 and supported by a large ecosystem of partners.
“We’re not saying OSFP is going away,” said Bechtolsheim. “It’s still ramping up and will run the next 10, 20 years I’m sure. It’s just not dense enough for AI moving forward.” He expects that the pricing between OSFP and XPO to be a “wash,” with XPO having fewer parts and more reliability, but not produced in the larger quantities that OSFP is already available at.
Going the Distance
Connecting everything within a dramatically densified data center is one challenge, while the sheer scale of new hardware for AI applications is swelling the amount and raw speeds per fiber beyond the racks and walls into connecting buildings.
“Over the past year or so, with GPU clusters for AI training models growing beyond 100,000 GPUs, it now means the AI training model is extending beyond a single facility into a second facility just to support this,” said Helen Xenos, Senior Director of Portfolio Marketing at Ciena. “You now need an optical network in between [the facilities] and you need to support an order or two orders of magnitude. When I say a lot of capacity, I mean hundreds of fibers of capacity.”
More capacity in a smaller footprint means Ciena is applying all of its tools to increase bandwidth, including high-capacity coherent pluggable technology moving to 1.6 Tbps, the photonic line system to now carry C & L bands to double the capacity across every single deployed fiber pair, and ultra-dense amplifiers to support the hundreds of new fibers.

Urgent demands for “scale across” connectivity between data center facilities has led Ciena to dramatically shrink amplifier site equipment for a 32x improvement. Source: Ciena
Pre-AI, an amplifier hut between two data centers was designed with chassis that could each support only one fiber pair or “rail,” which resulted in a hut that might support four rails per rack and that was sufficient for the bandwidth demands.
Scaling to hundreds of fibers between two data centers becomes a large challenge. “If you use the exact same technology and don’t make any changes, the customer would need to build 22 huts to support that capacity,” said Xenos. “It is not viable to start throwing more buildings, more power, more real estate. It’s not something that’s going to happen quickly and it’s way too cost prohibitive.”
Ciena’s solution, announced ahead of this year’s OFC, is RLS Hyper-Rail, a solution that packs up to 128 rails/pairs into a single rack. “Now we are able to achieve 32 times the density of what was available before, which drives down power significantly, 75% was the calculation,” said Xenos.
Hyper-Rail is expected to be purchased by large hyperscalers along with the service providers that are supporting them, especially across specific routes. Ciena is also bringing software to bear on the speed to deployment problem with an automated deployment optimizer to help with bringing up long-haul fiber routes more rapidly.
“Our customers tell us, do not underestimate the value of simple cookie-cutter deployments, because they need to deploy things very quickly, looking for hundreds of nodes a week or more,” said Xenos. “For challenging long-haul and submarine routes, submarine in particular, which normally take more than a week to turn up a channel because you have to do a frequency sweep across all the spectrum to know what type of capacity each wavelength can be supported across each part of a spectrum, it now does this automatically. It reduces time from weeks to minutes.”
Hollow Core, Multicore
Ciena and others are also working on next-generation fiber solutions, including hollow core and multicore solutions. The company has had a strong multi-year relationship with hollow core pioneer Lumenisity, now part of Microsoft, conducting extensive testing with Ciena’s hardware and the new medium.
“There are two near-term benefits of hollow core fiber,” said Xenos. “One of them is the lower latency, which is the number one reason why people are looking to deploy it. The second one is you could launch at a much higher signal power than what you could do today with regular fiber. What this means is that instead of having amplifier huts separated by 100 kilometers or 120 kilometers, maybe they’re separated by 300 kilometers. That changes the cost equation for building the network as well.”
Longer term, hollow core opens the opportunity to send signals across a wider range than the current C and L bands, providing the ability to put more data through a hollow core fiber, but it is too early for equipment that would deliver that benefit. But industry sources and hyperscalers have been reluctant to discuss hollow core deployments in public beyond pointing to carefully crafted blog updates released by Microsoft and publishing the occasional research paper.
Instead, multicore fiber moved into the mainstream at OFC this year, with Corning, AFL, Sumitomo Electric Industries, and TeraHop announcing a Multi-Source Agreement (MSA) that outlines the use of four-core multicore fiber design, performance, and interoperability requirements in data center applications.

Four core multicore fiber has emerged as a standard through a MSA between vendors, with formal definitions expected ratified by ITU by 2028. Source; Corning
“It’s clear to the industry that AI networks are evolving at an unprecedented rate, necessitating the ability to increase their optical density in scale up and scale out, just to increase the overall computational power of these AI clusters,” said Duane Robbins, Director of the Multicore Fiber Program at Corning Optical Communications. “It brings a whole new network on top of the legacy cloud network to interconnect these GPUs within a given campus and geographic area, ultimately creating larger interconnected clusters .”
The need for higher optical density is driving a 10-fold increase in the amount of fiber and pathways connected compared to traditional data centers. Being able to package four separate and distinct cores into a standardized 125 micron diameter fiber delivers more space-efficient ways to connect racks, rows, data halls, and network buildings.
“Scale across is another pain point for hyperscalers and local operators providing infrastructure,” said Robbins. “AI is driving substantial growth in the amount of data transmission in the scale across network in particular. In Northern Virginia, the sheer amount of rights-of-way and available ducts or microducts is quickly being drained. “At current compound annual traffic growth rates , legacy dark fiber is no longer available and newly deployed fiber cables are expected to become fully lit within a three-year time frame. Operators have been looking to replace existing fiber with slimmed down solutions that enable them to pack more strands into the same physical space. Multicore becomes the next step in increasing capacity using existing conduit.

AI and hyperscaler traffic is driving a 10 fold increase in the amount of fiber and pathways compared to traditional data centers, said Duane Robbins, Director of the Multicore Fiber Program at Corning Optical Communications, with compound growth expected to saturate existing networks within three years. Source: Corning
Wider adoption of the 4-core solution is expected to start over the next two to three years, according to Corning and other forecasts, as the ecosystem matures with equipment availability, testing, certification, and workforce education.
However, using multicore does require some additional hardware at this point in time, using a small form factor fan-in, fan-out (FIFO) device that takes a single 4 core fiber and breaks it out into individual single core fiber strands with standard LC connectors that plug into existing hardware.
Using multicore when compared to the same number of single core fibers leads to 75% fewer cables and connectors, up to 70% less cable mass, and about 60% lower installation times, according to Corning’s calculations, ultimately enabling a lower carbon footprint and faster uptime to place data centers into operations.
“Multicore is not a new principle,” said Robbins. “With this unprecedented growth in in bandwidth demand, driven by AI, it necessitates taking this from research into a true product solution set ready for deployment.”

Related Content

Brightspeed Business Launches 8 Gig Fiber to Power the Next Generation of AI-Driven Business Expanded fiber portfolio delivers the speed,…

Fiber for Breakfast Week 27: Optical Fiber and Cable Market Outlook: The Role of Hollow-Core and Multicore Fiber The fiber industry has been through several…

One of the ill-kept secrets of the data center world is the expanding construction and ownership of fiber to connect geographic sites. While building fiber miles is more expensive up front, owning a long-term asset with distinct control of the operating environment and costs for 30 or more years is a significant advantage, while also providing the opportunity for additional revenue through leasing dark and lit fiber to third parties.